Цель файла robots.txt - попросить поисковые системы краулить то, что надо. А что не надо - не краулить.
Краулить - это обойти, то есть исследовать.
Решение об индексации или неиндексации будет принимать поисковая система.
- Что надо краулить?
Да всё надо краулить.
Для начала все JAVA-скрипты, стили, шрифты и картинки.
Иначе бывает, что Google недоразбирает страницу и в кеше хранится какая-то дичь из кусков кода
User-Agent: *
Allow: /.js
Allow: /.css
Allow: /.woff
Allow: /.png
Allow: /*.jpg
У Битриксов есть поверье, что внутрях тоже обязательно надо всё-всё индексировать
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /local/components/
Allow: /local/cache/
Allow: /local/js/
Allow: /local/templates/
Дело хозяйское, я тоже так делаю, чтобы не быть особенным.
- Что не краулить?
То, что переменное и не уникальное.
Disallow: /cart/
Disallow: /checkout/
Disallow: /login/
Disallow: /profiles-add/
Disallow: /orders/
Disallow: /compare/
Disallow: /wishlist/
Disallow: /store_closed.html
Disallow: /payment/
Disallow: /app/
Disallow: /admin_panel
Disallow: /profiles-update/
Disallow: /app/
Disallow: /error/
Далее идёт интересная тема про GET-параметры.
Определение такое:
Это динамические аргументы в ссылке.
Они представляют собой набор пар «ключ=значение», передаются в URL-адресе после символа вопроса (?)
К примеру страница, на которую происходит переход из поиска Яндекса по домену SITE.ru будет выглядеть так
https://SITE.ru/?ysclid=[значение, то есть набор цифр и букв].

ysclid - это и есть GET-параметр.
Страница с GET-параметром является дублем материнской страницы.
При частых посещениях страниц с одинаковыми GET-параметрами и их значениями (например, кто-то выложил ссылку с GET-параметром в соцсети, и все ломанулись) эта страница может попасть в индекс и начать конкурировать с материнской за ранжирование запросов, то есть каннибаллить её.
Для всех поисковых систем, кроме Яндекса, все эти противные GET-параметры надо закрывать от краулинга с помощью директивы Disallow:
Можно попробовать просто добавить одну директиву
Disallow: /?
Но она закрывает от краулинга только первый GET-параметр, а они, твари, часто любят ходить паровозиком по два-три друг за другом.
Надо их закрывать индивидуально.
Для этого надо собрать их все.
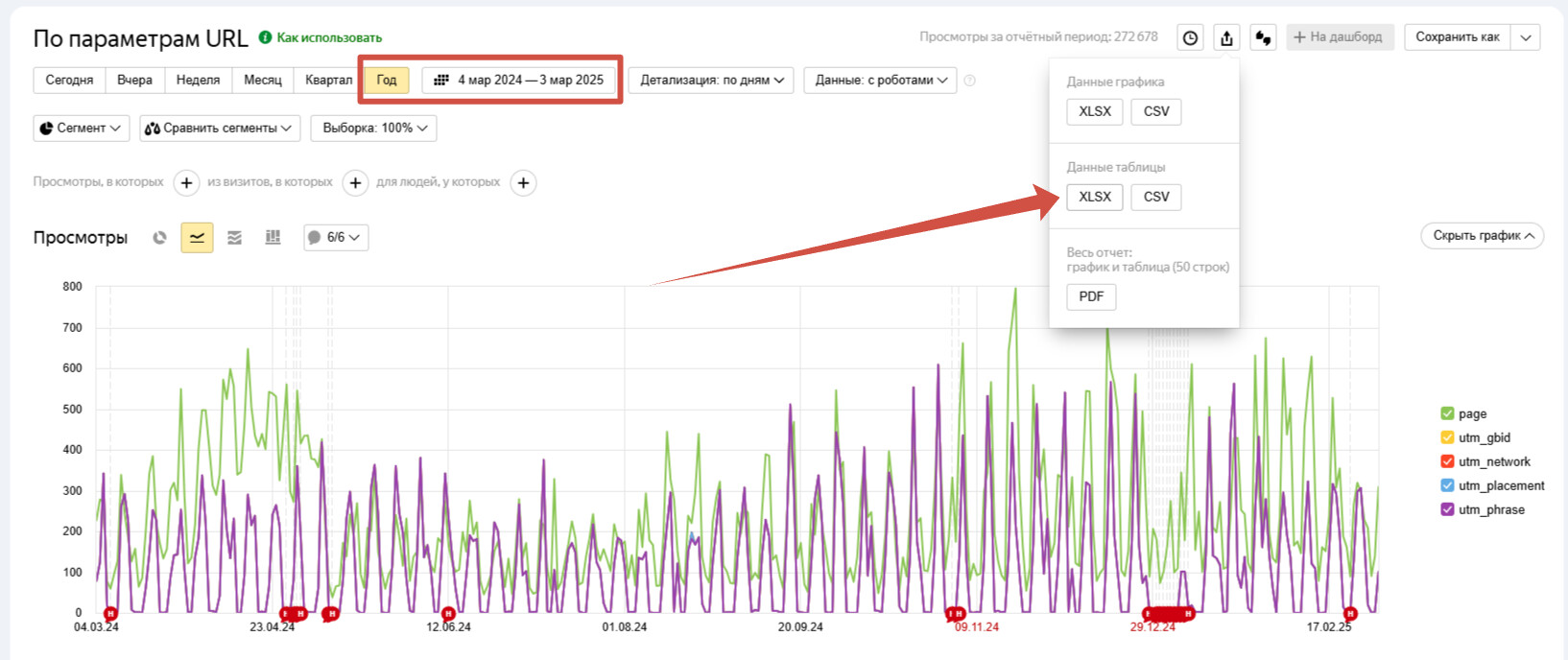
Идём в Метрику - Отчеты - По параметрам URL и выгружаем таблицу за год.
Из столбца Параметр URL удаляем дубли, добавляем в начало Disallow: ? а в конец =
Disallow: *?*auth=
Disallow: *?*back_url=
Disallow: *?*back_url_admin=
Disallow: *?*back_url_settings=
Disallow: *?*backurl=
То есть конструкция ? закрывает краулинг любых url, содержащих вопросительный знак.
А знак равенства указывает, что это именно GET-параметр.
Но директиву Disallow: надо делать в секции User-Agent: *
Это для всех, кроме Яндекса.
У Яндекса есть замечательная директива Clean-param:
Она как бы очищает url от GET-параметров.
Это нужно для аккумулирования поведенческих факторов пользователей на матерингской странице без GET-параметров.
Для Яндекса ПФ - важнейший фактор ранжирования.
Поэтому все GET-параметры перечисляем через & в строке после директивы Clean-param:
Длина строки - не более 500 знаков
Clean-Param: dispatch&search_performed&match
Может быть и 5, и 10 строк, сколько параметров соберёте.
Для Яндекса это критически важно, так как есть большое влияние хороших поведенческих от посетителей с Директа (если он есть, и если они оставляют хорошие поведенческие).
Чем больше хороших ПФ от посетителей с Директа - тем лучше ранжируется страница.
При условии, что ПФ аккумулируются именно на ней, а не распыляются по копиям с GET-параметрами.
Можно закрыть для краулинга от всех любых других ботов
User-Agent: SemrushBot
Disallow: /
User-Agent: MJ12bot
Disallow: /
User-Agent: AhrefsBot
Disallow: /
User-Agent: gigabot
Disallow: /
User-Agent: Gigabot/2.0
Disallow: /
Можно добавить Sitemap
Sitemap: https://SITE.ru/sitemap.xml
Можно ограничить скорость краулинга
Crawl-delay: 30
В общем, всё просто.