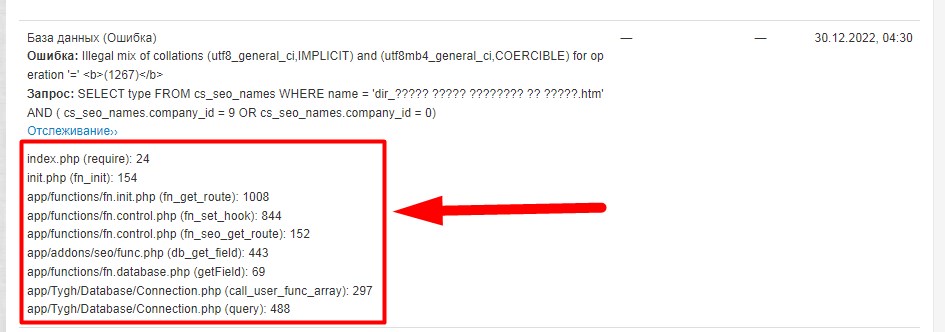
В журнале событий есть много ошибок вот такого рода
Как можно определить в следствии чего возникает ошибка которая записывается потом в журнале действий? На какой странице это происходит или что ее вызывает? Можно как-то узнать?
Поставил задачу на устранение таких ошибок программисту. А он мне написал “Напишите на какой странице возникают эти ошибки чтобы я мог исправить”… Но я не знаю что их вызывает, поэтому и обратился к нему за помощью… А он меня спрашивает…
Программист может понять откуда возникают ошибки которые записываются в журнале событий? Те строки что указаны для каждой ошибки в журнале событий под ссылкой “Отслеживание” (выделил красным на скрине выше) - они никак не могут помочь ему понять из-за чего или что вызывает эту ошибку?
Заранее благодарен за ответы
А программист с движком совсем не знаком? Пускай почитает внимательно на скрине. Странный, какой то урл с ютф-8 или спец. символами открывается, и как будете сам факт открытие урла даёт эту ошибку. Но оно пишет урл знаками ??? и действительно не видно урла. Много таких ошибок?
1 лайк
Да, в первую очередь посмотрите кодировку веб сервера, и кодировку базы и самой таблицы, которая указана в проблемном запросе. Там в принципе и указано в тексте на скрине, что БД не может обработать запрос с двумя кодировками urf8 и utf8mb4
Дополнительно еще потом посмотрите по логам доступа к серверу кто к вам долбится по таким ссылкам. Подозрительно как-то
В том то и беда, что не знаком с движком…
Есть ошибки где УРЛ с нормальными символами - не знаки вопросов, вот например
Вообще УРЛы с приставкой “goods” были на старой CMS с которой я и переехал на cs-cart. При переезде были созданы редиректы с УРЛ всех старых товаров с приставкой “goods” на новые УРЛ товаров в cs-cart.
Подозреваю, что данные ошибки появляються при переходе по старом УРЛ на товар… Может поисковый робот долбится по старым УРЛ которые в него в памяти… Но не понятно так ли это… и как можно узнать на какой странице возникает ошибка…
Написал запрос в поддержку хостеру. Они все проверили и вот что написали:
Кодировка сервера баз данных:
character_set_server utf8
collation_database utf8_general_ci
Кодировка базы данных:
character_set_database latin1
collation_database latin1_swedish_ci
Эти таблицы имеют кодироку отличную от utf8_general_ci:
cs_bm_blocks_content - кодировка - utf8mb4_unicode_ci
И терь вот думаю, почему у меня кодировка базы данных НЕ utf8, а какая-то непонятная - latin1 и collation_database НЕ utf8_general_ci а latin1_swedish_ci…
Подскажите, должна же быть кодировка баз данных вот такая?
character_set_database utf8
collation_database utf8_general_ci
Кодировку в столбце cs_bm_blocks_content программисты меняли для того чтобы емодзи можно было добавлять в тексте в нужном блоке… Сказали что если нужны емодзи то обязательно должна быть кодировка utf8mb4_unicode_ci - без нее емодзи не будут сохраняться и отображаться на сайте. Так ли это?
Так и на вашем скрине есть знак вопроса. По факту это необязательно знак вопроса, так может отображаться битый символ
А на что именно нужно обращать внимание? В логах же просто IP адрес указывается… Как понять кто именно запрашивал УРЛ страницы?
Это к администратору хостинга - может посоветуют чего. Если скажут какой бот стучится и он вам не нужен, можно будет его заблочить
Спасибо. А по кодировке БД можете подсказать?
У меня сейчас такая, как оказалось:
А должна быть такая?
И по кодировке чтобы емодзи работали, все верно?
значит базу создали со значениями по умолчанию - для забугорных latin1 как стандарт, а MySQL AB - шведская компания (поэтому и collation_database latin1_swedish_ci по дефолту)
а вот на mb4 как раз и ругается - тут выбирайте, или эмодзи и нотисы, или ни того, ни другого
1 лайк
А что такое “Нотисы”? 
Не пойму почему ругается если нет обращения к этой таблице…
В таблице cs_bm_blocks_content с кодировкой - utf8mb4_unicode_ci располагается контент из блоков, которые в макетах. А в ошибках с кодировкой показывает УРЛ с которых когда-то настраивались редиректы…
Это же разные таблицы…
А если вот тут
Вот тут взять код эмодзи - Full Emoji List, v15.0
А тут с html эмодзи получить entity Text to HTML Entities - cryptii v2
И потом код html сущности вставлять в нужном месте в контент, то получается мы ж не сам эмодзи будем вставлять, а его код. ,
И тогда в базе данных таблица может быть в кодировке - utf8_general_ci и в ней будет храниться код эмодзи, а на сайте в браузере он уже должен отображаться не как код, а как эмодзи - или не верно я понимю?