Блин это какая маржа должна быть на товаре, что бы помимо комиссии МП ещё и рекламу проплачивать))
1 лайк
У меня клиент есть, мы размещаем товары на озоне и временами запускаем рекламу внутри Озона . И скажу я вам что у нас за месяц выходит более 6 тысяч на рекламу.
На Озоне жуткие и бешенные комиссии. Если на Маркете Яндекс фиксированная стоимость размещения до 15 кг. То на Озоне за каждый литр 30 руб, если размещать 5 литровую позицию. Помимо того, что они утилизируют без спроса товары и отписываются что неправильная упаковка товара, даже забрать не дают. Сами товар нам портят, а потом за наши деньги и еще утилизируют. Получается за декабрь наши товары утилизировали на 4 тысячи и за утилизацию удержали 3 тысячи. Итого 7 тысяч. Я так ругалась.
Мы считали , не мене 200%
Да примерно такая маржа и должна быть, у нас позиция в ИМ 1800, а в МП 2900-3200, чтобы комиссии покрыть и в акциях можно было участвовать.
1 лайк
Добрый вечер! Подскажите пожалуйста есть смысл закупать ссылки для нового сайта ? И если да то можете порекомендовать сервис, можно в личку! Спасибо за внимание
Во-первых, как неожиданно оказалось, ссылки работают и на Google, и на Яндекс, но в разной степени.
То есть буквально неделю назад мы все были уверены, что Яндексу ссылки не важны, а вот материалы в сливочной утверждают, что у Яндекса 29 факторов, где в названии есть Link. Какой приоритет они имеют в окончательной формуле ранжирования - неизвестно, но они там есть, то есть Яндекс на ссылки как миниум поглядывает.
Для Google ссылки всегда имели ключевое значение после возраста.
Во-вторых, ссылками новорег сложно вытянуть из печочницы, разве только большими объемами морд с Сапы или Википедией. Самое разумное - купить релевантный дроп под подклейку С СОХРАНЕНИЕМ ВОЗРАСТА.
В 2022 году Google активно апдейтил алгоритмы, и Link Spam update вроде бы, исходя из названия, должен как-то повлиять на покупателей ссылок. Но статистика неоднозначная, кого-то пессимизировало, кого-то отнюдь. Кроме того, Google не может быть уверен в том, что покупка плохих ссылок - это действие владельца сайта, а не его конкурентов, пытающихся понизить сайт в выдаче.
При этом надо понимать, что на РФ Google выделяет миниум вычислительных мощностей, ибо тут для них денег нет, и алгоритмы работают в полнакала, без фанатизма.
Покупать ли ссылки - да, если не можете получить “естественным путём”, как этого хотел бы Google. Но я бы советовал понемногу, и арендные, чтобы их быстро отменить, если что-нибудь пойдет не так. И обязательно проверять хотя бы trust/spam.
Но более эффективно покупать релевантные дропы (хотя сейчас все шибко умные стали, крайне редко можно найти что-нибудь приемлимое), и/или использовать многоуровневые прокладки для прогона Хрумером.
7 лайков
Спасибо за информацию!
Всем и Дмитрий здравствуйте. Подскажите откуда у меня взялась дубль страница
https://skidki-dnya.ru/produkty-pitaniya/page-2/
Вот оригинал
https://skidki-dnya.ru/produkty-pitaniya/
Вебмастер сообщил. И как ее удалить?
На кнопках пагинации nofollow нет, на второй и третьей странице есть каноникал, но и noindex нет, поэтому никто не запрещает вебмастеру ее проиндексировать, а потом через некоторое время удалить как неканоническую - это нормально.
Это у вас с существующей страницей, у меня вебмастер посерьезнее работает - индексирует страницы домен.ру/страница_товара?page-2 - вот что озадачивает.
Благодарю за обратную связь. Я понять не могу, вебмастер сам ее сформировал или она у меня в системе есть? Покажите на примере это как:
А Вы сможете мне подсказать в какой папке на сервере хранятся где все ссылки сайта? Ну или где они вообще хранятся. И то мне надо восстановить удалённые.
Казалось бы, что такого может быть интересного в техническом аудите сайта?
Иногда бывает.
При краулинге лягушкой нашел заблокированные в robots.txt обычные страницы, вполне себе нормальные.
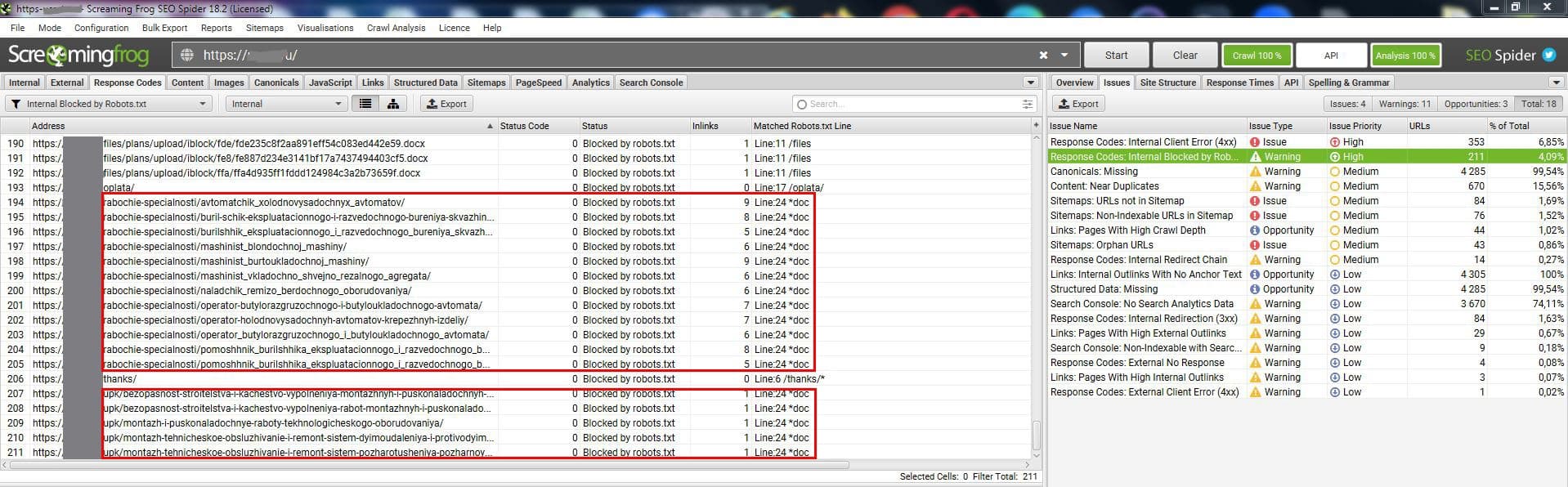
Смотрю, где заблокированы - Line:24 *doc
Открываю robots.txt, вижу, что он с ошибками (один общий User-agent: *, и в нем же Clean-param, который только для Яндекса, например)
Строка 24
Disallow: *doc
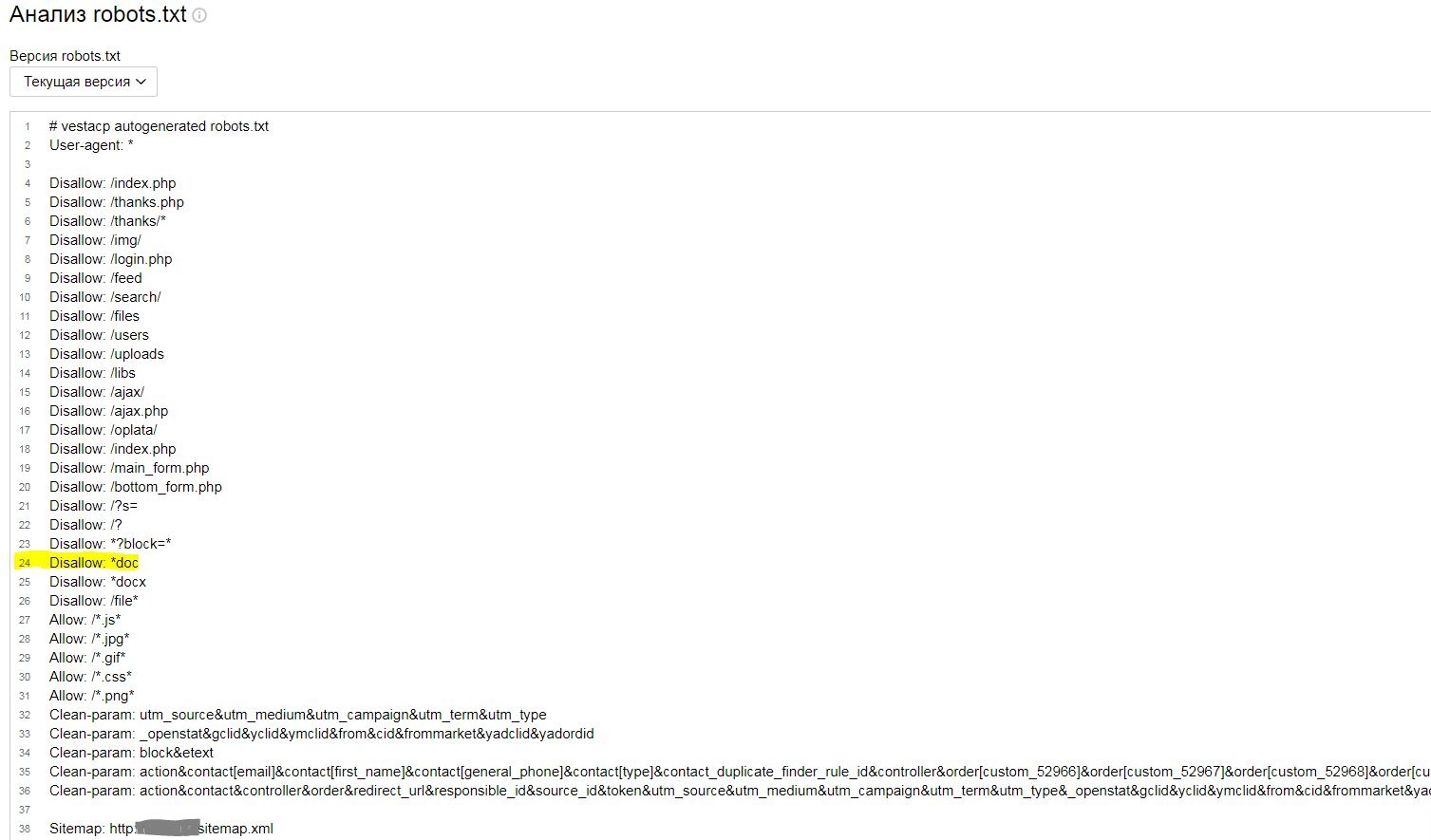
То есть мы хотели закрыть индексацию (точнее краулинг ботами ПС) файлы формата .doc, но забыли поставить точку, поэтому все url, содержащие эти три буквы - блокируются.
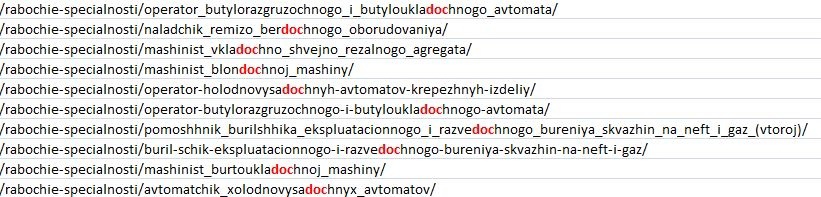
При этом краулинг всех файлов из папки /file в принципе запрещен в строке 26 директивой Disallow: /file*, так что строки 24 и 25 избыточные.
Чувствую себя очень наукоёмким. Пойду, наверное, пива выпью, чтобы немного снизить уровень умственности до приемлимого ![]()
4 лайка
Идеальный на ваш взляд Роботс в студию, пожалуйста!
Нет такого, к сожалению. Это как обувь, есть масс-маркет, а есть индивидуальное изготовление.
Можно попробовать приблизиться к идеалу, но среди сеошников до сих пор, например, нет общего понимания, как работать со страницами пагинации. На некоторых ТГ-каналах во избежание холиваров даже запрещают обсуждение национальности, религии и пагинации ![]()
Могу посоветовать статью Артура Корсакова robots.txt для CMS Wordpress Joomla OpenCart Битрикс на 2019 год
Кроме этого советую смотреть в своей Метрике страницы входа, чтобы отследить get-параметры, добавлять их в Clean Param и обязательно проверять потом в Вебмастере, как сработало.
И ещё надо понимать, что директивы в robots.txt в целом как бы рекомендательные, типа, дорогие поисковые боты, пожалуйста, не надо краулить вот это и вот это, а вот это и это надо.
Но поисковый системы давно считают себя умнее кожаных мешков и сами принимают решение, что и как надо краулить, и что потом индексировать.
3 лайка
У меня вот такой стоит
User-agent: *
Disallow: *?selected_section*
Disallow: *?show_not_found_notification*
Disallow: /*collection_product
Disallow: /search/
Disallow: /variant
Disallow: /*wishlist.delete
Disallow: /*attachment
Disallow: /*items_per_page
Disallow: /app/
Disallow: /store_closed.html
Disallow: /*?subcats*
Disallow: *product_id*
Disallow: /*?match*
Disallow: *features_hash*
User-agent: Yandex
Clean-param: combination&match&subcats&pcode_from_q&pshort&pfull&pname&pkeywords&search_performed&q&dispatch&features_hash&product_id&post_redirect_url&promotion_id&page&sort&sort_by&sort_order&layout&return_url&block&position&s_layout&redirect_url&utm_sourse&frommarket&items_per_page&with_images&selected_section&clid&prev_url&n_items&show_not_found_notification&utm_medium&utm_campaign&utm_content&utm_term&block&source®ion®ion_name&placement&roistat&rf_parent_post_id&utm
Clean-param: &object_type&object_id&obj_prefix&route&tag_id&limit&path&variation_id&sl&product_review_id&variant_id&manufacturer_id&category_id&post_id&order&abt_in_popup&cookies_accepted&page_id&template&frmgrably
Host: https://домен
Sitemap: https://домен/sitemap.xml
1 лайк
Все get-параметры можно прибить одной директивой Disallow: *?*
5 лайков
Что входит в полный технический SEO-аудит сайта:
Краулинг ScreamingFrogSEOSpider, поиск дублей, малоценных или маловостребованных страниц, ошибок HTTP, региональность, анализ текстовой релевантности, robots.txt, sitemap.xml, htaccess, и всего такого, что мешает Вашему сайту расти и давать прибыль.
Заказать SEO-аудит можно, точнее даже нужно, у меня. На данный момент за последний год я сделал 55 таких аудитов.

Подскажите стоит ли упоминать в описаниях Товаров, именно Товаров, о самом магазине.
Например
Ляляля, много текста о товаре, а потом - покупайте эту приблуду у нас, в интернет магазине"Имя магазина" т.к. у нас лучшие условия, грамотные консультанты, удобная доставка и т.д.
Как к такому относятся Яндекс, Гугл и покупатели?
Никакого смысла в этом нет, покупатель уже знает, что он именно в вашем магазине.
Яндекс и Google не очень любят повторяющиеся малозначащие куски теста. Таким образом Вы снижаете уникальность страниц внутри сайта, не причиняя пользы посетителям.
2 лайка