Вот то рекомендует вэбмастер:
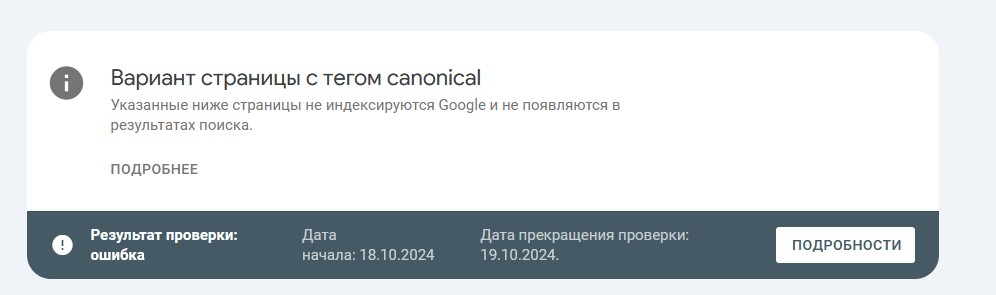
Некоторые страницы с GET-параметрами в URL дублируют содержимое других страниц (без GET-параметров). Например, https://example.com/tovary?from=mainpage дублирует https://example.com/tovary. Из-за их обхода информация о важных для вас страницах может медленнее передаваться в поисковую базу, что может влиять на состояние сайта в поиске.
Посмотрите примеры. Если в поиске есть дубли из-за GET-параметров, рекомендуем использовать директиву Clean-param в robots.txt, чтобы робот игнорировал незначащие GET-параметры и объединил все сигналы со страниц-копий на основной странице. Когда робот узнает о внесенных изменениях, страницы с незначащими GET-параметрами пропадут из поиска.
Можно проще, в админке он. Веб сайт - Seo вкладка Robots.txt просто пропишите
Clean-param: review_rate&selected_section если были ранее записи просто добавьте без пробела к уже существующим правилам через &review_rate&selected_section
Ссылка ведет на документацию в гугл, а там ничерта не понятно!
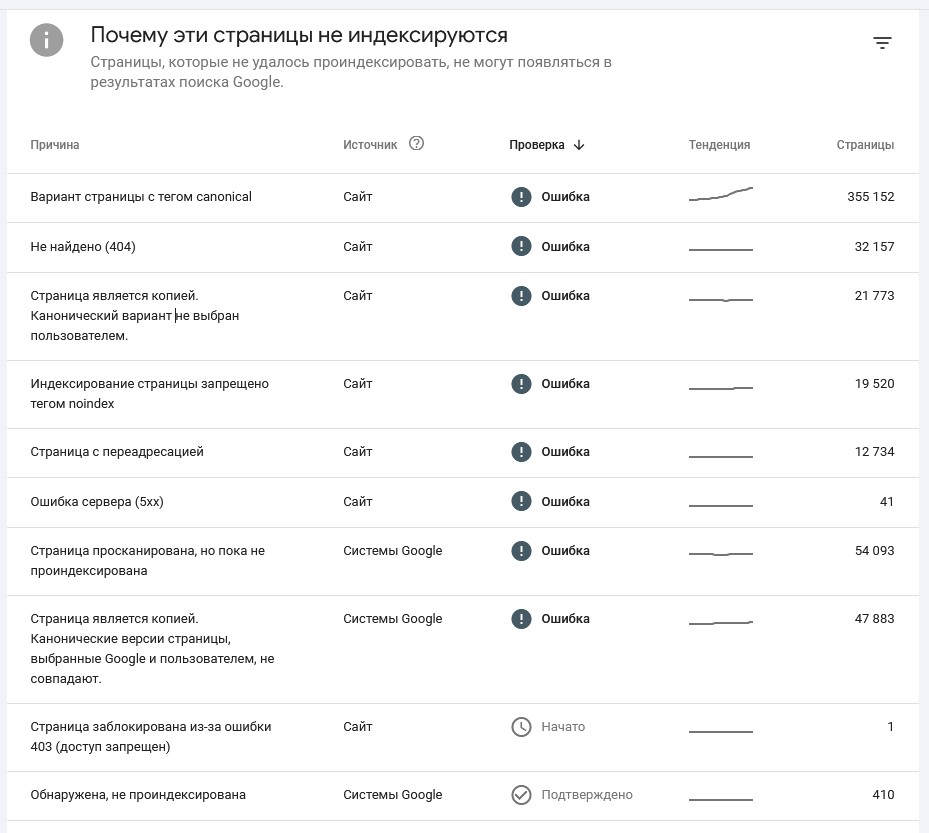
Страница является копией. Канонический вариант не выбран пользователем.
Эта страница дублирует другую, но не указана в качестве канонической. Робот Google считает канонической другую версию этой страницы, поэтому дубликат не появляется в результатах поиска. Узнать, какой ресурс робот Google считает каноническим, можно при помощи инструмента проверки URL.
Это не считается ошибкой, поскольку Google не показывает копии страниц. Если канонической выбрана неверная страница, отметьте правильную страницу как каноническую. Чтобы страница не считалась копией той, которая занесена в индекс Google как каноническая, их контент должен существенно различаться.
Некоторые страницы с GET-параметрами в URL дублируют содержимое других страниц (без GET-параметров). Например, https://example.com/tovary?from=mainpage дублирует https://example.com/tovary. Из-за их обхода информация о важных для вас страницах может медленнее передаваться в поисковую базу, что может влиять на состояние сайта в поиске.
Посмотрите примеры. Если в поиске есть дубли из-за GET-параметров, рекомендуем использовать директиву Clean-param в robots.txt, чтобы робот игнорировал незначащие GET-параметры и объединил все сигналы со страниц-копий на основной странице. Когда робот узнает о внесенных изменениях, страницы с незначащими GET-параметрами пропадут из поиска.